 主页
主页





随着AI发展如火如荼,高校作为基础研究的主阵地,正扛起推进AI研发和应用的大旗,如何构建AI所需的超高算力并加速科研成果转化早已提上日程。
就在去年11月,国内高校最强AI计算平台正式开放,峰值算力达16PFLOPS,面向上海交通大学各院系和科研机构提供高效的算力支撑。
这一AI计算平台由上海交通大学网络信息中心计算部(以下简称“计算部”)打造,目前已支持20多位研究团队开展AI和典型HPC等科研创新应用工作。
近日,智东西与上海交通大学网络信息中心工程师程盛淦进行深入交流,试图了解国内高校最强AI计算平台背后的故事。

▲上海交通大学网络信息中心机房
国内高校最早AI计算平台,全队列使用率接近100%
上海交大网络信息中心的前身是上海交通大学计算中心,始建于1973年,是我国高校建立最早、规模最大的计算中心之一。
早在2013年,该中心就搭建了超级计算机π1.0,这是一台异构HPC系统,峰值性能达262TFLOPS,在2013年6月全球TOP500超算排行榜中位列第158名,是当时的国内高校第一、上海市地区第一。
当AI研发风潮席卷学术圈,更多院系希望借助AI加速推进自己的研发成果,有限的算力资源和繁复的硬件部署流程成为挡在他们面前的主要阻碍。
此时,一个稳定成熟且拥有强大算力基础的资源调度平台成为刚需,它可以按需进行AI算力供给和分配,同时有专门的技术和运维团队予以支持。
这将使更多研究团队在满足AI计算需求的同时,无需自行购买硬件设备,也不必在环境配置和应用部署耗费时间,而是更加专注于自己的科研项目本身。
作为是国内最早涉足AI领域的高校之一,上海交通大学有着丰富的AI计算需求。
恰逢超级计算机迭代之际,上海交通大学AI计算平台即依托从2018年开始立项的π2.0来建设,它也是国内最早搭建的高校统一AI计算平台之一。
上海交大AI计算平台面向全校提供稳定强大的GPU资源调度,同时也支持校外用户来申请计算资源,峰值算力达16PFLOPS。

▲上海交通大学网络信息中心服务器
π2.0集群从2019年4年正式启动设备的安装部署,程盛淦也是在此期间开始参与这一新项目的推进。经过机房改造、扩容制冷设备、安装调试等一系列流程,π2.0自2019年11月起正式向校内开放。
程盛淦透露说,2019年12月上海交大AI计算平台整个队列的使用率接近100%,GPU利用率达到70%,AI相关负载达到75%,其余25%是一些高性能计算负载。
搭建AI计算平台,上海交大的三个优势
在高校科研环境中,搭建AI计算平台并非易事,至少面临三方面的挑战。
其一,海量数据和巨大计算需求。AI和HPC都需要海量数据,要求AI计算平台具备较高数据处理能力、存储能力和网络能力。
其二,环境配置。AI和HPC应用的框架、库、驱动程序等复杂组件更新迭代速度很快,需消耗大量人力来维护和编写整个平台的软件栈。
其三,资源调度。AI计算平台需具备完善的资源调度系统和强健的集群管理工具,能够灵活调度集群算力资源,避免不同负载间相互干扰,提升应用运行效率。
不过,这对于拥有多年集群部署经验的交大计算部来说并非难事。程盛淦表示,在打造AI计算平台方面,其团队有三个核心优势:
首先,在搭建第一代超级计算机π1.0时,网络信息中心已经积累了丰厚的用户基础、强大的运维团队和成熟的集群管理经验,能够确保集群系统的稳定运行。
其次,上海交大是最早开始提供GPU计算服务的高校之一。GPU擅长处理大规模深度学习训练以及部分典型HPC任务,而上海交大在采用GPU做基础科学研究方面有多年的积累,对先进GPU设备和校内计算需求都有较好的理解。
此外,计算部还提出一个创新的“交大型”服务模式。计算部借助超级计算机π向高水平科研用户提供丰富的技术支持,和多学科研究进行紧密融合,支撑和催化学校的科研发展。
高算力集群背后:DGX-2带来性能爆发
聚焦到AI计算平台本身,这么高的算力如何实现呢?在部署底层基础设施的过程中,上海交大计算部又曾站在哪些选择的交叉口上?
从和程盛淦的交流中,我们提炼了其中较为重要的三点。
1、硬件选型:8台DGX-2,打造超强AI算力集群
由于GPU在深度学习训练性能和完整的生态上,相比其他计算设备优势更明显,交大计算部选择使用8台NVIDIA DGX-2服务器来提供底层算力支撑。

▲NVIDIA DGX-2机柜
这一选择主要有两方面考量。一是GPU在深度学习训练性能和完整的生态上本身具备优势,二是上海交大在使用GPU计算设备和搭建计算机集群上有长期经验。
而DGX-2又是NVIDIA GPU超高计算和存储能力的集大成者,NVIDIA通过采用多种互联技术,有效提升GPU间以及集群间的互联带宽。
每台DGX-2内置16张NVIDIA Tesla V100 GPU,程盛淦特别提到,DGX-2搭载了NVIDIA NVSwitch创新互联技术,最多可支持16块GPU互联,并将GPU间的总双路带宽提升到2.4TB/s。
DGX-2还采用了可扩展架构,使得模型的复杂性和应用的规模不受传统架构局限性的限制,8台DGX-2就使得深度学习张量计算能力达到16PFLOPS,本地NVMe存储达到300TB,从而可以应对众多复杂的AI和HPC的挑战。

DGX-2的硬件性能优势,使其可以支持此前GPU服务器难以支持的大规模AI和HPC应用。
比如,上海交大生命科学学院的一个团队在做针对单颗粒冷冻电镜图片处理的软件框架Relion,用到的数据集量级高达1TB。这对普通GPU服务器来说过于庞大,但在上海交大AI计算平台的帮助下,该团队通过使用DGX-2全机6节点8卡的配置,顺利完成了计算任务。
2、软件优化:协同硬件,提升GPU有效利用率
有了高性能的硬件基础设施,还要思考如何能更好保障GPU有效利用率。对此,程盛淦所在的团队重点做了三方面的工作。
(1)搭建了DGX-2和π 2.0集群共享的并行文件系统,这个文件系统加上DGX-2本地NVMe存储,保证数据传输速率能承担大规模数据量处理任务。
(2)根据AI计算平台的实际情况,采用SLURM作业调度系统和Singularity容器技术相结合的方式, 保证用户作业相对独立,有效实现资源隔离,以最高的效率为用户提供最佳性能的应用支持。
(3)通过NGC为用户提供经过特别优化处理的容器镜像,进一步优化软件部署流程。
在DGX-2上直接运行应用可能面临编译流程复杂、应用优化需与最新硬件适配、AI领域实验复现和环境管理难等问题,因此用户需要一个性能优异、开箱即用的应用部署方案,而NGC是一个很好的选择。
NGC是NVIDIA针对GPU优化的AI和HPC软件堆栈的容器平台,提供超过50种相关应用和框架的镜像,简化了软件部署流程和软硬件协同调优流程。
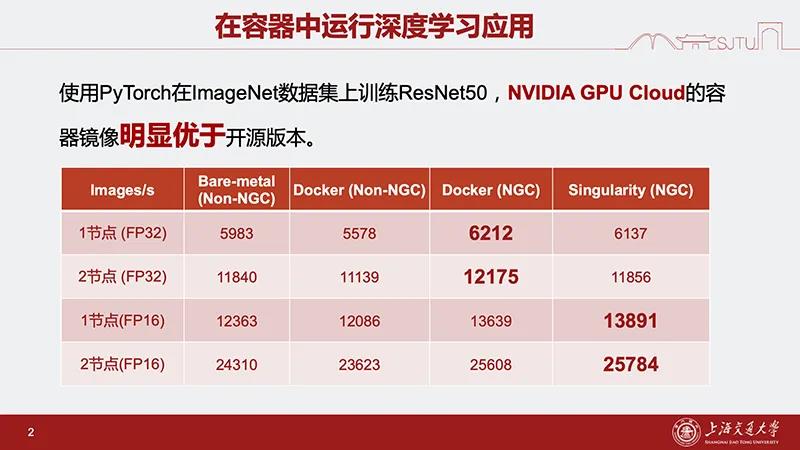
例如,使用PyTorch在ImageNet数据集上训练ResNet50,NGC的容器镜像上速度上明显优于开源版本。
3、体验升级:与超算平台统一入口
由于AI计算平台是依托π2.0集群搭建的,是为AI计算平台打造一个独立入口,还是让它和超算系统使用统一的入口,计算部特意做了测试。
经测试用户反馈,统一入口在管理效率和用户体验感方面都更胜一筹。
对于超算老用户来说,超级计算机π1.0的用户无需学习新知识,即可快速掌握AI计算平台的使用方法。
对于校内新用户来说,统一入口也能降低他们在使用超算平台和AI计算平台上的学习成本。
最高提升1.8万倍!超强AI平台助推多项科学研究效率大幅提升
AI计算平台的开放,将做AI处理任务的门槛进一步降低,有助于帮助更多科学研究人员借助AI计算实现更高效地进行科研工作。
此前,π1.0作为校级高性能计算公共服务平台,曾支持理、工、生、医的多篇研究发表于《Science》、《Nature》等高水平期刊上。如今AI计算平台支持的多项科研项目,论文也已经投往各大学术会议和期刊。
截至本月,上海交大AI计算平台已经帮助上海交大人工智能研究院、Bio-X研究院、密西根联合学院等多院系的研究团队去优化计算AI及HPC应用,最高将科研效率提升1.8万倍。
程盛淦向我们介绍了其中的四个典型应用。
1、AI应用:二值化神经网络
该研究电子信息和电气工程学院的一个团队所做。他们利用Tensor Core混合精度进行加速并优化了数据读取,使用1台DGX-2达到每秒6826张图的训练速度,比早先在有4张NVIDIA 1080Ti的服务器上跑,速度(103张/秒)提升66.3倍。
2、AI应用:用强化学习加速类AlphaGo训练
做这一研究的团队同样来自电子信息和电气工程学院,通过采用8台DGX-2、使用NVIDIA MPS技术并调整了负载均衡。
原来用2张NVIDIA Tesla v100卡训练50万局自我对弈需要35天,现在仅用34.8小时就能完成训练。
3、AI应用:基于深度学习的空气污染预报
该研究团队来自环境科学与工程学院。他们使用Conv-LSTM模型结合编解码结构,学习全国范围内排放、气象分布到污染物分布情况的映射关系。
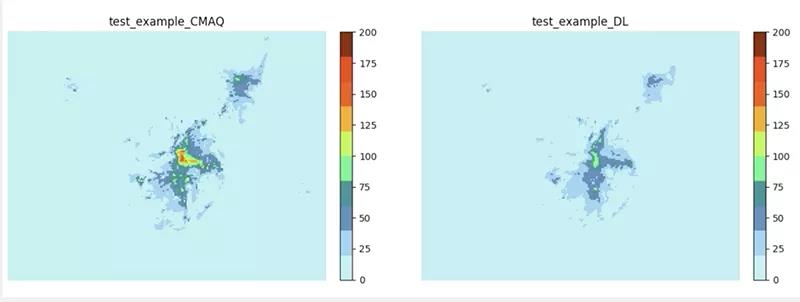
使用DGX-2单机后,系统训练迭代速度比之前使用1张NVIDIA P100快31.6倍。
4、HPC应用:求解声子玻尔兹曼方程
除了为AI训练提供算力,AI计算平台还能支持HPC应用。比如密西根联合学院就利用该平台来求解声子玻尔兹曼方程。
原先用CPU做这一计算需要2周,使用8台DGX-2后,计算时间压缩到2分钟,比此前速度足足提升1.8万倍。
结语:AI计算平台将催化更多科研创新
上海交通大学网络信息中心计算部主任林新华表示:“AI for Science作为科研第四手段已经成为一种国际趋势,而世界著名高校、科研单位在新建计算平台时对数值计算和AI计算都予以了充分考虑。像NVIDIA DGX-2和NGC容器平台这样的先进的硬件配置和软件堆栈方案,解决了在高校科研环境下搭建AI计算平台面临的诸多挑战,加速了学科进步,推动了学科融合。”
林新华认为,AI计算平台不仅是一个面向全校的计算服务平台,更是一个学科交叉以及科研创新平台,可以在此基础上深入开展典型高性能计算应用、AI、大数据等应用科研创新工作。
接下来,上海交通大学网络信息中心计算部希望借助AI计算平台与更多用户深度合作,展开更多研究领域的深层次合作,解决更多科学计算难题,进一步助力提高交大科研水平。
(文章首发于微信公众号“智东西”)





























